本文來自:芯東西,作者: ZeR0
那個打造出世界最大計算芯片的硅谷明星創企Cerebras Systems,正將“做大做強”的戰略貫徹到極致!
今日凌晨,Cerebras Systems宣佈推出世界上第一個人類大腦規模的AI解決方案,一台CS-2 AI計算機可支持超過120萬億參數規模的訓練。相比之下,人類大腦大約有100萬億個突觸。
此外,Cerebras還實現了192台CS-2 AI計算機近乎線性的擴展,從而打造出包含高達1.63億個核心的計算集羣。

Cerebras成立於2016年,迄今在14個國家擁有超過350位工程師,此前Cerebras推出的世界最大計算芯片WSE和WSE-2一度震驚業界。

WSE-2採用7nm工藝,是一個面積達46225平方毫米的單晶圓級芯片,擁有2.6萬億個晶體管和85萬個AI優化核,無論是核心數還是片上內存容量均遠高於迄今性能最強的GPU。
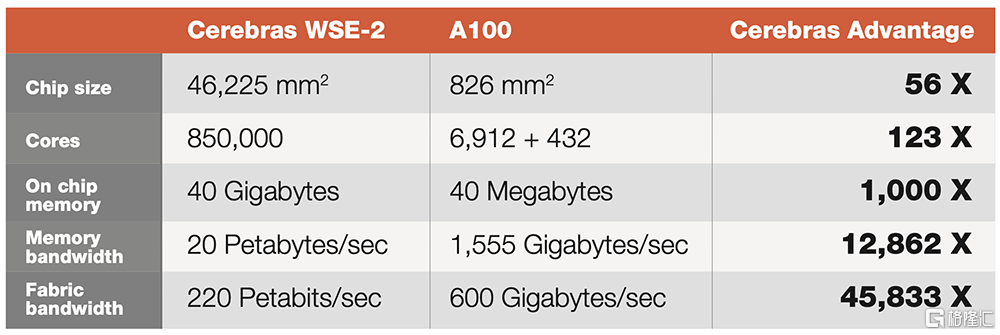
WSE-2被集成在Cerebras CS-2 AI計算機中。隨着近年業界超大規模AI模型突破1萬億參數,小型集羣難以支撐單個模型的高速訓練。
而Cerebras最新公佈的成果,將單台CS-2機器可支持的神經網絡參數規模,擴大至現有最大模型的100倍——達到120萬億參數。

在國際芯片架構頂會Hot Chips上,Cerebras聯合創始人兼首席硬件架構師Sean Lie詳細展示了實現這一突破的新技術組合,包括4項創新:
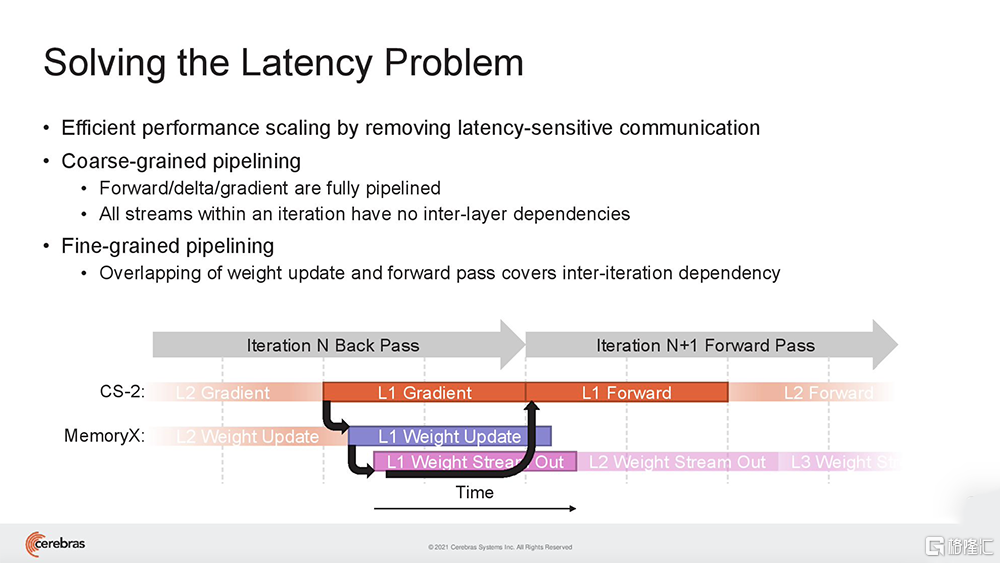
(1)Cerebras Weight Streaming:一種新的軟件執行架構,首次實現在芯片外存儲模型參數的能力,同時提供像片上一樣的訓練和推理性能。這種新的執行模型分解了計算和參數存儲,使得擴展集羣大小和速度更加獨立靈活,並消除了大型集羣往往面臨的延遲和內存帶寬問題,極大簡化工作負載分佈模型,使得用户無需更改軟件,即可從使用1台CS-2擴展到192台CS-2。
(2)Cerebras MemoryX:一種內存擴展技術,為WSE-2提供高達2.4PB的片外高性能存儲,能保持媲美片上的性能。藉助MemoryX,CS-2可以支持高達120萬億參數的模型。

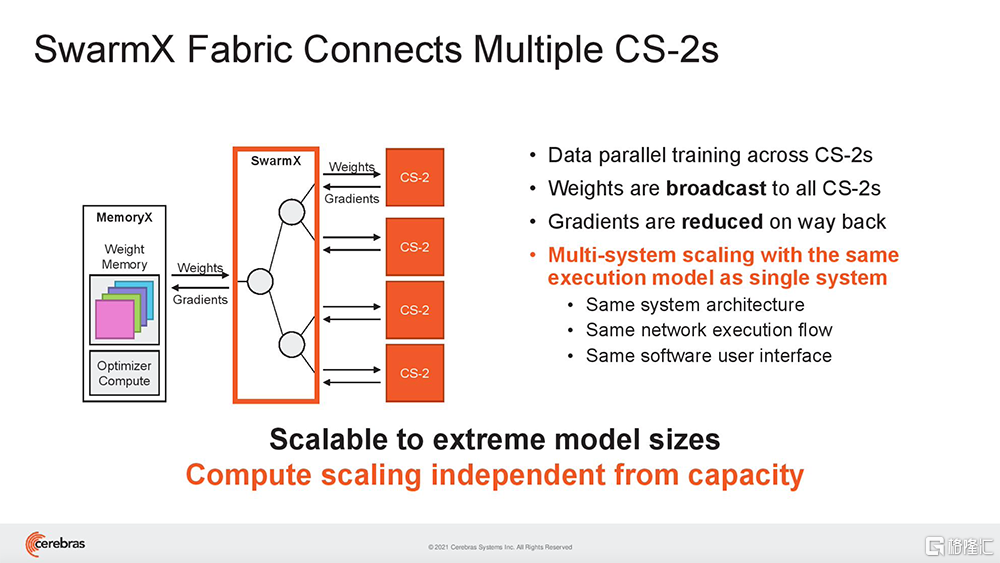
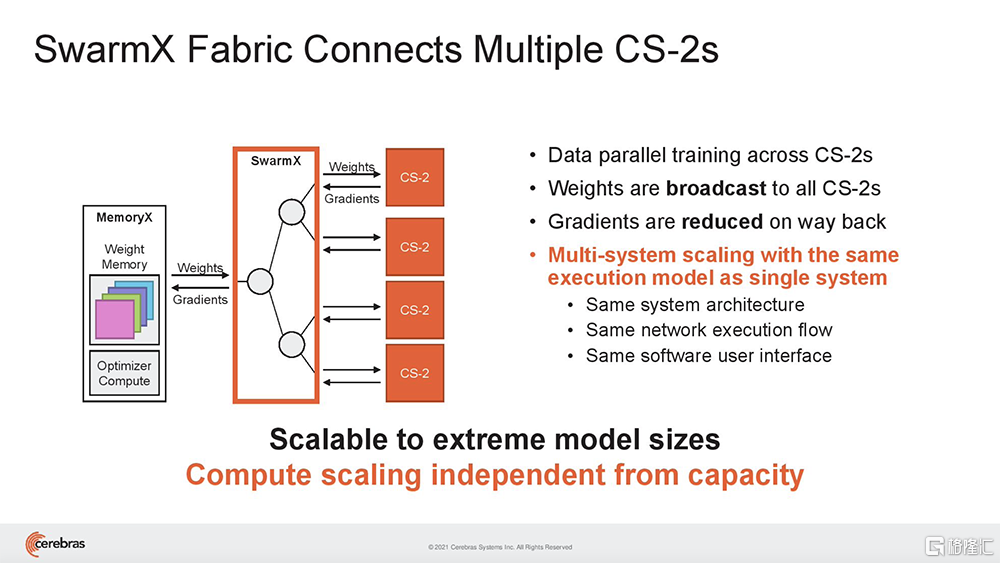
(3)Cerebras SwarmX:是一種高性能、AI優化的通信結構,將片上結構擴展至片外,使Cerebras能夠連接多達192台CS-2的1.63億個AI優化核,協同工作來訓練單個神經網絡。
(4)Selectable Sparsity:一種動態稀疏選擇技術,使用户能夠在模型中選擇權重稀疏程度,並直接減少FLOP和解決時間。權重稀疏在機器學習研究領域一直頗具挑戰性,因為它在GPU上效率極低。該技術使CS-2能夠加速工作,並使用包括非結構化和動態權重稀疏性在內的各種可用稀疏性類型在更短的時間內生成答案。

Cerebras首席執行官兼聯合創始人Andrew Feldman稱這推動了行業的發展。阿貢國家實驗室副主任Rick Stevens亦肯定這一發明,認為這將是我們第一次能夠探索大腦規模的模型,為研究和見解開闢廣闊的新途徑。
01.
Weight Streaming:存算分離,
實現片外存儲模型參數
使用大型集羣解決AI問題的最大挑戰之一,是為特定的神經網絡設置、配置和優化它們所需的複雜性和時間。軟件執行架構Cerebras Weight Streaming恰恰能降低對集羣系統編程的難度。

Weight Streaming建立在WSE超大尺寸的基礎上,其計算和參數存儲完全分離。通過與最高配置2.4PB的存儲設備MemoryX結合,單台CS-2可支持運行擁有120萬億個參數的模型。
參與測試的120萬億參數神經網絡由Cerebras內部開發,不是已公開發布的神經網絡。
在Weight Streaming中,模型權重存在中央芯片外存儲位置,流到晶圓片上,用於計算神經網絡的每一層。在神經網絡訓練的delta通道上,梯度從晶圓流到中央存儲區MemoryX中用於更新權重。
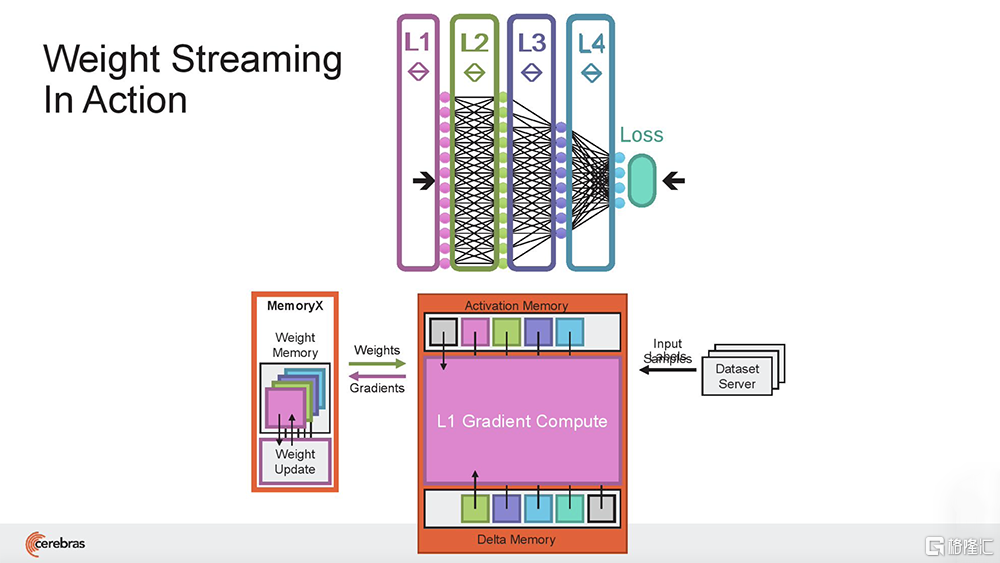
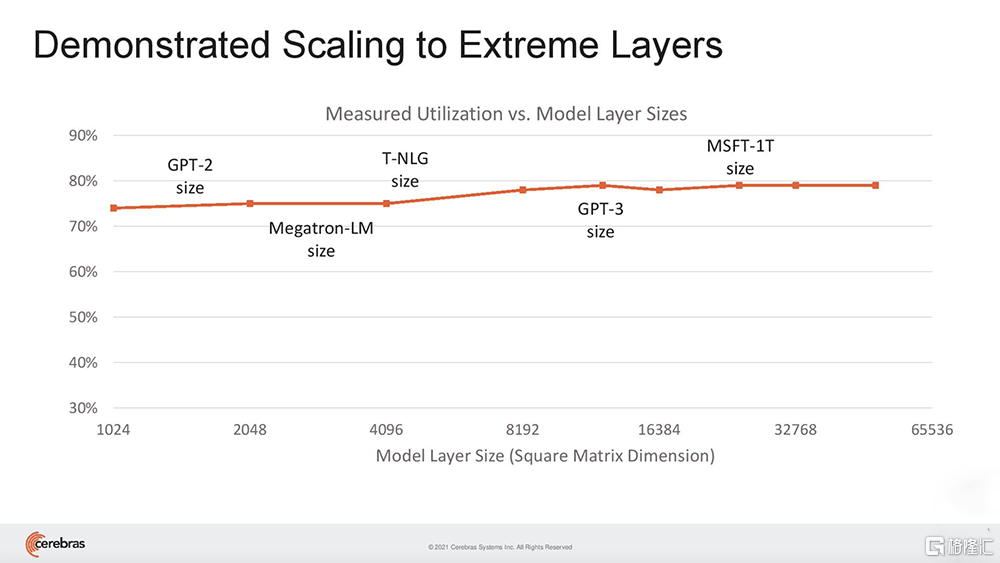
與GPU不同,GPU的片上內存量很小,需要跨多個芯片分區大型模型,而WSE-2足夠大,可以適應和執行超大規模的層,而無需傳統的塊或分區來分解。
這種無需分區就能適應片上內存中每個模型層的能力,可以被賦予相同的神經網絡工作負載映射,並獨立於集羣中所有其他CS-2對每個層進行相同的計算。
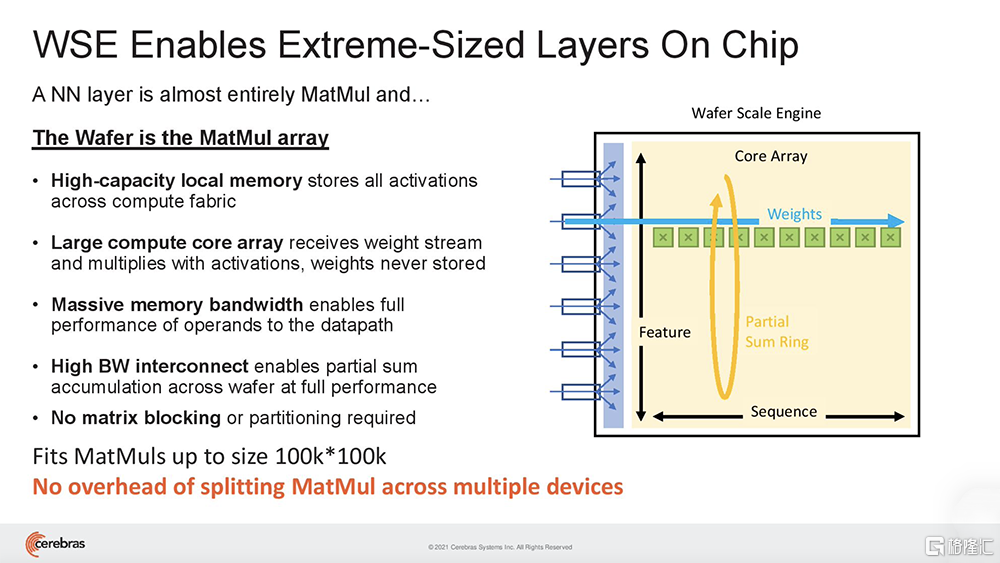
這帶來的好處是,用户無需進行任何軟件更改,就能很方便地將模型從運行在單台CS-2上,擴展到在任意大小的集羣上。也就是説,在大量CS-2系統集羣上運行AI模型,編程就像在單台CS-2上運行模型一樣。
Cambrian AI創始人兼首席分析師Karl Freund評價道:“Weight Streaming的執行模型非常簡潔、優雅,允許在CS-2集羣難以置信的計算資源上進行更簡單的工作分配。通過Weight Streaming,Cerebras消除了我們今天在構建和高效使用巨大集羣方面所面臨的所有複雜性,推動行業向前發展,我認為這將是一場變革之旅。”
02.
MemoryX:實現百萬億參數模型
擁有100萬億個參數的人腦規模級AI模型,大約需要2PB字節的內存才能存儲。
前文提及模型參數能夠在片外存儲並高效地流至CS-2,實現接近片上的性能,而存儲神經網絡參數權重的關鍵設施,即是Cerebras MemoryX。

MemoryX是DRAM和Flash的組合,專為支持大型神經網絡運行而設計,同時也包含精確調度和執行權重更新的智能。
其架構具有可擴展性,支持從4TB至2.4PB的配置,支持2000億至120萬億的參數規模。
03.
SwarmX:幾乎線性擴展性能,
支持192台CS-2互連
雖然一台CS-2機器就可以存儲給定層的所有參數,但Cerebras還提議用一種高性能互連結構技術SwarmX,來實現數據並行性。
該技術通過將Cerebras的片上結構擴展至片外,擴展了AI集羣的邊界。
從歷史上看,更大的AI集羣會帶來顯著的性能和功率損失。在計算方面,性能呈亞線性增長,而功率和成本呈超線性增長。隨着越來越多的圖形處理器被添加到集羣中,每個處理器對解決問題的貢獻越來越小。
SwarmX結構既做通信,也做計算,能使集羣實現接近線性的性能擴展。這意味着如果擴展至16個系統,訓練神經網絡的速度接近提高16倍。其結構獨立於MemoryX進行擴展,每個MemoryX單元可用於任意數量的CS-2。
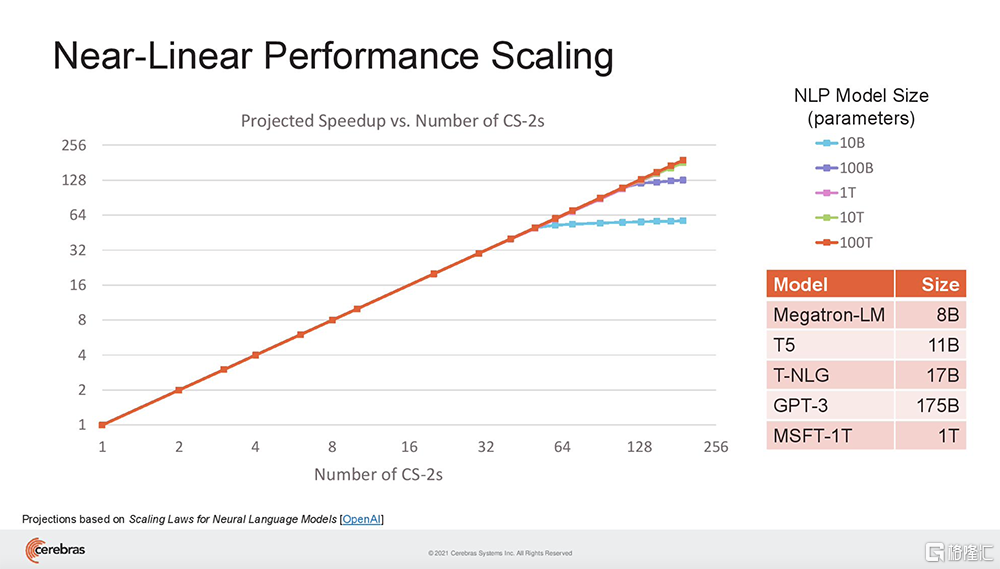
在這種完全分離的模式下,SwarmX結構支持從2台CS-2擴展到最多192台,由於每台CS-2提供85萬個AI優化核,因此將支持多達1.63億個AI優化核的集羣。
Feldman説,CS-2的利用率要高得多。其他方法的利用率在10%~20%之間,而Cerebras在最大網絡上的利用率在70%~80%之間。“今天每個CS2都取代了數百個GPU,我們現在可以用集羣方法取代數千個GPU。”
04.
Selectable Sparsity:動態稀疏
提升計算效率
稀疏性對提高計算效率至為關鍵。隨着AI社區努力應對訓練大型模型的成本呈指數級增長,用稀疏性及其他算法技術來減少將模型訓練為最先進精度所需的計算FLOP愈發重要。
現有稀疏性研究已經能帶來10倍的速度提升。
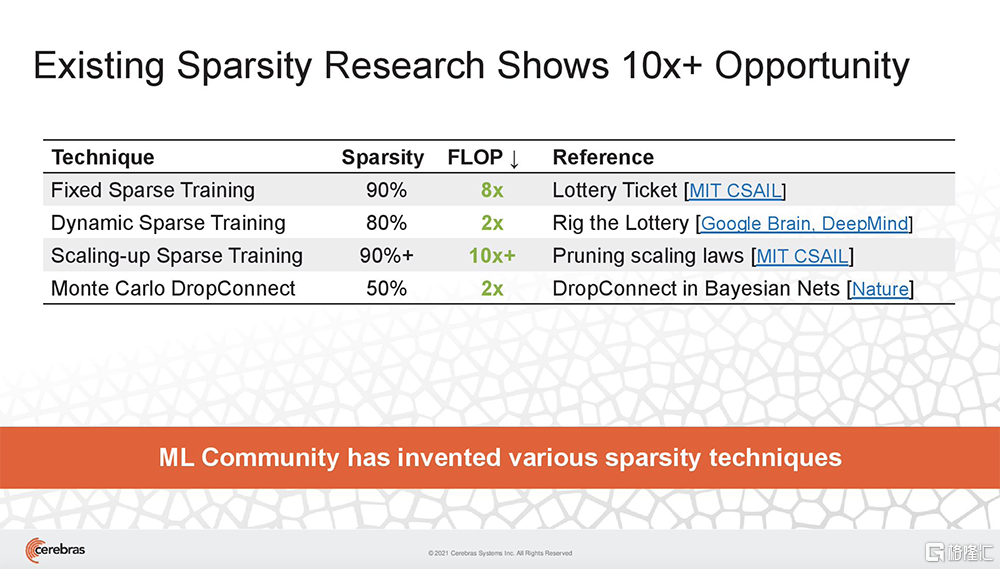
為了加速訓練,Cerebras提出一種新的稀疏方法Selectable Sparsity,來減少找到解決方案所需的計算工作量,從而縮短了應答時間。
Cerebras WSE基於一種細粒度的數據流架構,專為稀疏計算而設計,其85萬個AI優化核能夠單獨忽略0,僅對非0數據進行計算。這是其他架構無法做到的。
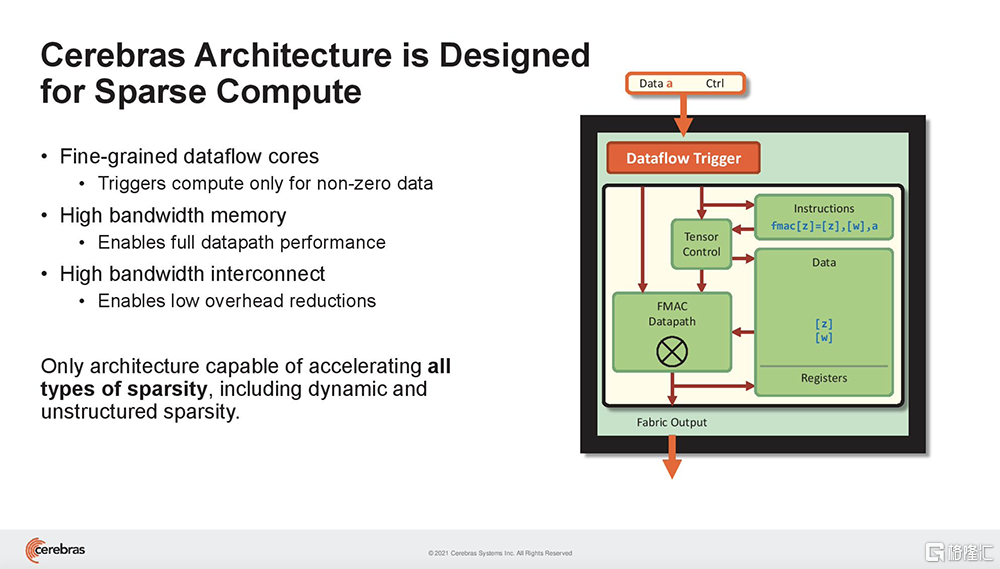
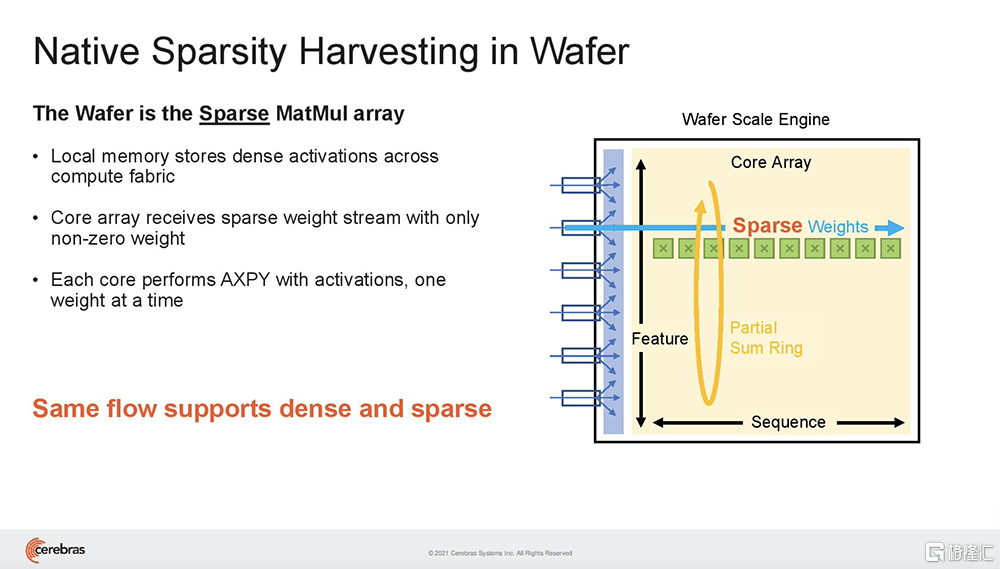
在神經網絡中,稀疏有多種類型。稀疏性可以存在於激活和參數中,可以是結構化或非結構化。
Cerebras架構特有的數據流調度和巨大的內存帶寬,使此類細粒度處理能加速動態稀疏、非結構化稀疏等一切形式的稀疏。結果是,CS-2可以選擇和撥出稀疏,以產生特定程度的FLOP減少,從而減少應答時間。
05.
結語:新技術組合讓集羣擴展不再複雜
大型集羣歷來受設置和配置挑戰的困擾,準備和優化在大型GPU集羣上運行的神經網絡需要更多時間。為了在GPU集羣上實現合理的利用率,研究人員往往需要人工對模型進行分區、管理內存大小和帶寬限制、進行額外的超參數和優化器調優等複雜而重複的操作。
而通過將Weight Streaming、MemoryX和SwarmX等技術相結合,Cerebras簡化了大型集羣的構建過程。它開發了一個全然不同的架構,完全消除了擴展的複雜性。由於WSE-2足夠大,無需在多台CS-2上劃分神經網絡的層,即便是當今最大的網絡層也可以映射到單台CS-2。
Cerebras集羣中的每台CS-2計算機將有相同的軟件配置,添加另一台CS-2幾乎不會改變任何工作的執行。因此,在數十台CS-2上運行神經網絡與在單個系統上運行在研究人員看來是一樣的,設置集羣就像為單台機器編譯工作負載並將相同的映射應用到所需集羣大小的所有機器一樣簡單。
總體來説,Cerebras的新技術組合旨在加速運行超大規模AI模型,不過就目前AI發展進程來看,全球能用上這種集羣系統的機構預計還很有限。


More Content